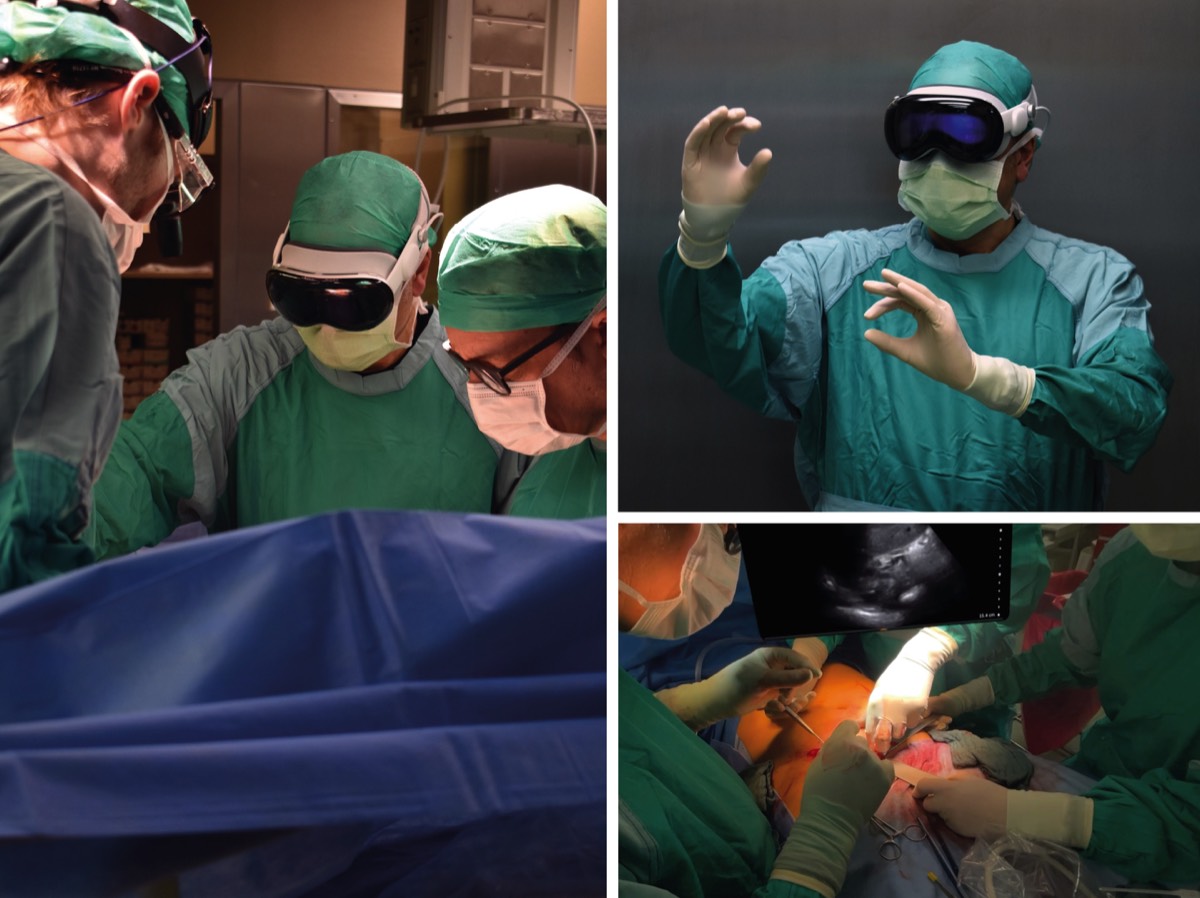
PERISKOP brings hospital stays to life with immersive 360° videos

This gives patients the opportunity to familiarise themselves with the environment before their stay, learn about spatial and organisational processes, and experience potentially anxiety-provoking situations in advance. The aim is to reduce uncertainty, create a feeling of familiarity and support individual preparation for the hospital stay.
The project also examines how VR-supported information services can improve patient education and be integrated into clinical routine in the long term to support hospital staff.
The studies are based on three stereoscopic 360° films on the clinical areas of anaesthesia, intensive care and childbirth, produced at original locations at Charité – Universitätsmedizin Berlin. The films are not only aimed at patients: hospital staff can also use the recordings to gain the patient's perspective and thus deepen their empathy and understanding of the clinical experience. Each sub-study follows its own research design, tailored to the respective clinical situation and target group. Among other things, the studies examine preoperative anxiety, the subjective feeling of preparation, and effects on empathy and communication in everyday clinical practice. Data collection is currently underway. The project is funded by the Charité Foundation through the Max Rubner Prize 2024.
Learn more about PERISKOP via periskop.experimental-surgery.de/
We thank Stiftung Charité for their support and making this project come alive!